¿Qué es NLP / procesamiento de lenguaje natural?
El procesamiento de lenguaje natural, o NLP por sus siglas en inglés, es un campo de las ciencias de la computación, la inteligencia artificial y la lingüística, que estudia y modela el reconocimiento del habla, la comprensión del lenguaje natural y la generación de éste, creando productos como auto-traductores, auto-resumidores, chatbots, analizadores de curriculums, generadores de fake-news, etc.
¿Qué es y para qué se usa un corpus?
En NLP, un corpus es un archivo de texto muy grande; actualmente el estado del arte en español esta en unos 1.500 millones de palabras. Estos corpus, escritos originalmente por humanos, se utilizan para entrenar los algoritmos de procesamiento de lenguaje natural, o insumos intermedios para estos, como word embedings.
¿Qué influencia tienen los corpus?
El 2016, Microsoft lanzó en twitter Tay, un chatbot que “se volvió” neonazi en pocas horas y tuvo que ser desconectado. En rigor, Tay “aprendió” a ser neonazi utilizando la tuitósfera como corpus.

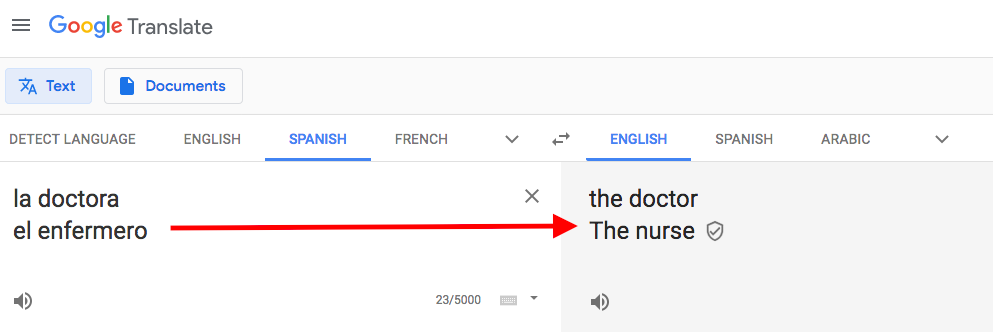
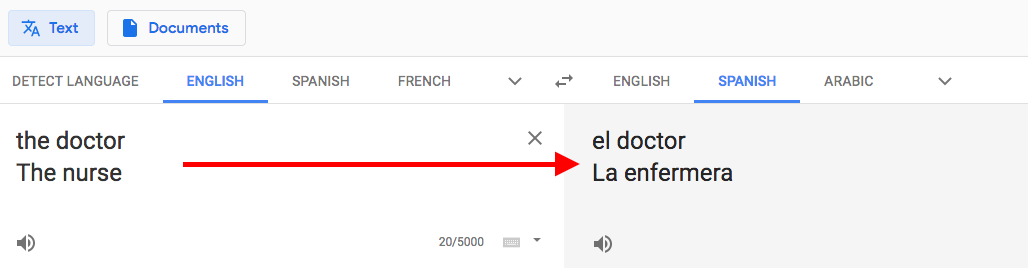
Los algoritmos de procesamiento de lenguaje natural, menos extremos pero aun sesgados, se encuentran en uso en todas partes. Un ejercicio ya clásico para mostrar estos sesgos es ir a google translator y pasar el texto “la doctora y el enfermero” del español al inglés, y luego de vuelta al español.
¿Por qué balancear un corpus?
Entendiendo que los corpus influencian fundamentalmente los principales productos contemporáneos de NLP, y estos productos se extienden de forma cada vez más rápida y vasta en nuestra sociedad, en la medida que queramos hacerla más diversa e inclusiva se hace fundamental construir y liberar un corpus balanceado. Existe un sesgo de género en los corpus, y los algoritmos lo reproducen. Para corregirlo, es necesario incorporar a los corpus de los cuales aprenden los algoritmos textos que no tengan ese sesgo de género (o que los tengan inversamente, de modo de balancearlos).
Siguiendo en la línea de los sesgos de género en las profesiones, si una universidad implementa un chatbot para asesorar a quienes postulen a sus carreras, éste se comportaría muy distinto si se entrenara con un corpus que contuviese una relación de 1/1 en las palabras ingeniera/ingeniero a si se lo hiciera con uno que contenga una relación 1/1000? Pero, para conseguir un corpus con el que entrenar al algoritmo que contenga una relación 1/1, sería necesario echar mano de bibliotecas y/o textos que utilicen la palabra ingeniera con esta relación (o más, a favor de “ingeniera”).
El balance de género es un comienzo, pero el mismo problema se extiende a sesgos de raza, capacidad, jerarquía, etc.
¿Cómo balancear un corpus?
Propongo partir por explorar fuentes alternativas de calidad. Actualmente existen recursos como bibliotecas feministas abiertas y otras similares de otras áreas. El desafío inicial es, entonces, cuantificar su extensión (contar su cantidad de palabras) y estimar la escala de los textos desde perspectivas minoritarias “balanceadoras”.
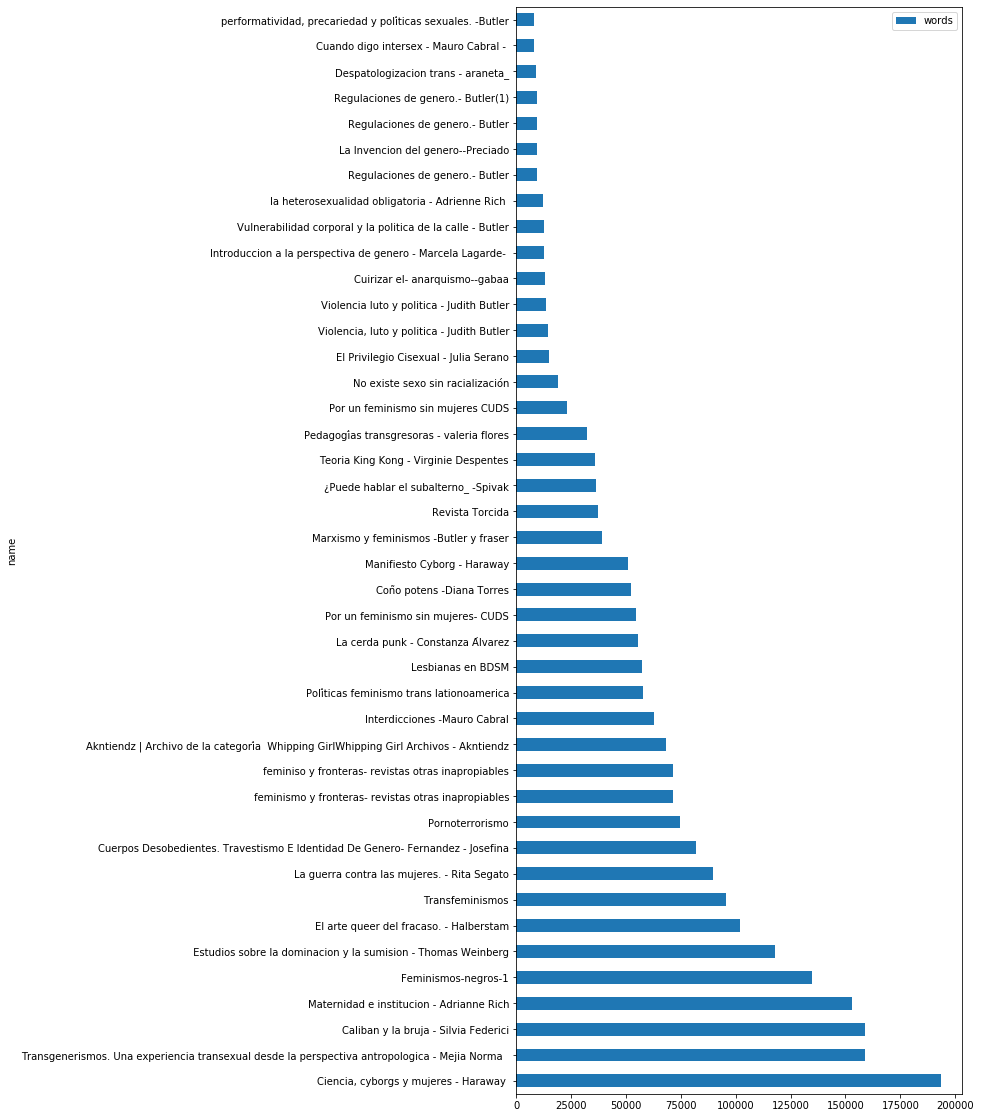
Para quienes se sientan cómodos (o curiosos) en Python, los invito a revisar el notebook que he creado para realizar este conteo de palabras, y he cuantificado como prueba, una colección de textos feministas, escritos por mujeres.
Si no te sientes cómodo ejecutando el notebook, tienes una biblioteca o colección libre desde perspectivas minoritarias y te gustaría ayudar, mándame tus archivos, por wetransfer, mega, ftp, etc. (ya que por peso no deberían caberte en un mail), y yo los puedo analizar.