Me acabo de graduar del nanodegree en deep learning de udacity, para quienes les interesa, esta es un reseña sobre el mismo.
Intro / contexto:
Mi orientación al aprendizaje en la vida es fuertemente autodidacta. En pregrado abandoné ingeniería comercial para emprender con un software propio, que improvisé aprendiendo php. A partir del año pasado decidí estudiar ciencias de datos, y con la finalidad de validar mi conocimientos en el área, me persuadieron a estudiar algo formalmente.
Busqué bastante, pues dentro de las ofertas formales no transaría mi voluntad de aprender de verdad. Por esas fechas, estaba interesada en deep learning, pero me estaba costando. Por lo que el nanodegree en deep learning de udacity, me convenció de que podría cumplir ambos objetivos: reconocimiento formal y aprendizaje nuevo.
Udacity
Di mis primeros pasos en ciencia de datos siguiendo un curso introductorio de udacity, y me cautivó su equilibrio entre teoría y práctica, y el formato de video + git. El fundador de udacity —Sebastian Thrun-, fue el fundador de googleX, donde lideró equipo del automóvil autónomo. Y el año pasado fue portada de la revista Nature, con un modelo de diagnósticos dermatológicos en deep learning que se incluye como parte del nanodegree. Es profesor de Stanford también, institución que me tenía seducida siguiendo cs301n.
Deep learning nanodegree
Los profesores son de primer nivel: Sebastian Thrun, Ian Goodfellow, Jun-Yan-Zhu, Andrew Trask y Cezanne Camacho. Unos más famosos que otros, pero todos muy buenos. Todos los videos se pueden bajar, y al final uno se queda con varios repositorios de código propio, y también de profesores.
Buena base
Para quienes no teníamos una base matemática dura, recomendaban el curso gratuito linear álgebra refresher que comencé un mes antes, y concluí con una librería propia (así enseñan, haciéndote programar librerías) de vectores que suma, determina ortogonalidad, etc., en n dimensiones. Muy apropiada, pues el primer capítulo y prueba del nanodegree es escribir un modelo de deep learning en Numpy, que es es la librería base de matrices de Python. Un trabajo muy manual, de base, pero que me valió la pena para darme seguridad con las operaciones algebraicas que sustentan el deep learning.
Nucleo: general y acotado
Lo troncal son los capítulos de redes convulsionales –Convolutional neural networks–, redes recurrentes (RNN y LSTM), y redes generativas adversariales.
Las redes convulsionales (CNN) son la base para el procesamiento de imágenes u otras matrices 2d o 3d (fotografías, planos, video, etc), la materia incluye: transfer learning: que permite entrenar modelos apoyándose en modelos de terceros para otras aplicaciones (reduce el tiempo de entrenamiento en órdenes de magnitud), auto-encoders: que permiten generar compresiones/codificaciones para dominios específicos (por ejemplo: para caras serían cosas como color de ojos, tipo de nariz, forma de las cejas, etc), y style transfer: que es una técnica similar para combinar el estilo de una imagen con el contenido de otra.
Las redes recurrentes (RNN / LSTM), que se utilizan para modelar secuencias de datos (series de tiempo, texto, etc), son arquitecturas que pueden parecer muy complejas, pero las explican bien. En ese capítulo se hace bastante trabajo de procesado de lenguaje natural, incluyendo embeddings y word2vec.
Y, para coronar, las redes generativas adversariales (GANs) son presentadas por su inventor (Ian Goodfellow). En esta arquitectura se trabaja con una red que genera contenido y otra, que lo clasifica como real o no. De esta forma, ambas redes aprenden juntas (comparten gradiente). La evaluación de este capítulo fue la más cool, había que crear un algoritmo que generara cara humanas. Debo aclarar que, a fin de reducir el tiempo de desarrollo y entrenamiento de semanas a días, las hice en 32x32 pixeles y 3/4 del error ideal, pero con las mismas técnicas se podría escalar a 256x256 con mayor realismo.
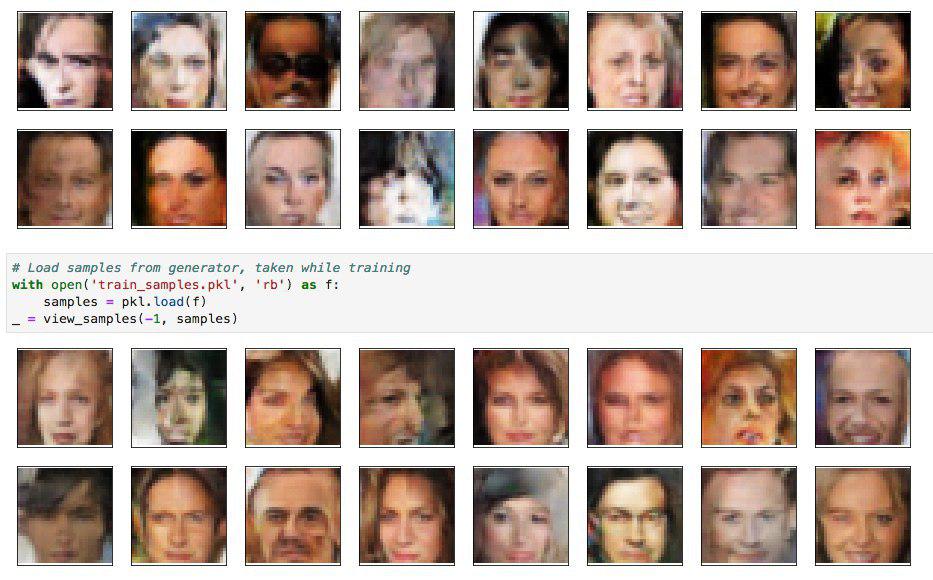
También se nos enseñó otros conceptos transversales como weight initialization e hyperparameters optimization. En general hay muchas referencias a papers sobre deep learning, y una orientación a que los implementemos, lo que me funcionó bastante bien. Implementé varias cosas desde papers (arquitecturas, políticas de ajuste de learning rates, etc), y me quedó gustando como práctica dentro del desarrollo de modelos.
Contenido de última generación
La materia incluye tecnologías totalmente contemporáneas. Por ejemplo CycleGANs y Transformers/Attention son modelos publicados durante el 2018, y se abordan con buena profundidad en el nanodegree. En general, estos contenidos de última generación van después de la evaluaciones de cada capítulo, por lo que, a quienes les compliquen, igualmente pueden aprobar el programa, pero para quienes somos nos obsesionamos más, podemos estudiarlos, aprenderlos y codearlos.
El costo de un contenido tan reciente es que había un puñado de bugs en los ejercicios (yo misma documenté uno en la knowledge base), pero es un costo un bajo, e inevitable, a cambio de un currículum tan al día.
Deployement: Sagemaker
El último capítulo del nanodegree es sobre deployment, y se enfoca en Amazon sageMaker. Entiendo que puede ser muy valioso para quienes vienen de la academia y la investigación, pero, para mí, viniendo del desarrollo de software donde la filosofía devOps es: “quien lo desarrolla, lo despliega“, me pareció poco valioso.
Tampoco me impresionó sageMaker como plataforma. Usarlo es casarse con una corporación gigante y un ecosistema privativo, y a pesar de estas desventajas, el costo por hora de máquinas con NVIDIA K80 (base de GPU para deep learning) fue $1.26/h comparado con el $1.20/h que cobra floydhub. Mis caseros, que son una empresa pequeña, fundada y atendida por científicos de datos (quienes contestan los tickets han hecho más modelos que yo) y donde corres directamente el framework open source de tu gusto (tensoflow o pytorch).
Lo que faltó o se podría mejorar
Hay dos temas que no son triviales de aprender, y me habría gustado que estuvieran en el programa: paralelización en pytorch (multi-GPU/multi-máquinas) e Entrenamiento con baja memoria.
La plataforma de comunidad no está bien moderada, por lo que el chat es desordenado, en algunos canales los mentores están muy presentes y en otros, todo lo contrario. Y la knowledge base es poco usada y desordenada también.
En cualquier caso, todo esto es órdenes de magnitud menor al lado de la calidad y contemporaneidad del contenido.
Conclusión
Recomiendo totalmente este nanodegree a personas curiosas y auto-motivadas en su aprendizaje, aunque no necesariamente para quienes necesitan una estructura más formal y tradicional (clases presenciales, evaluaciones en fechas fijas, etc). Los contenidos son avanzados y actualizados, los profesores de clase mundial y tiene mucho material complementario ya sea para nivelarte en lo básico, profundizar en lo más complejo y explorar en lo tangencial.